Kompresia je súkromný prípad kódovania, ktorého hlavnou charakteristikou je, že výsledný kód je menší ako pôvodný. Proces je založený na hľadaní opakovania v informačnej sérii a zachovaní len jedného spolu s počtom opakovaní. Napríklad, ak sa sekvencia objaví v súbore ako "AAAAAA" zaberajúci 6 bajtov, bude uložený ako "6A", ktorý zaberá 2 bajty v algoritme kompresie RLE.
História procesu
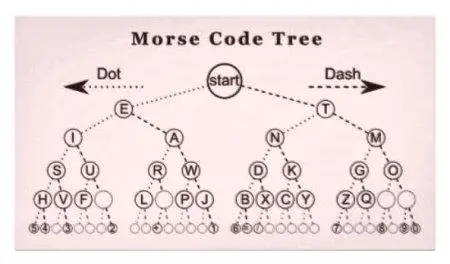
Morseov kód, vynájdený v roku 1838, je prvým známym prípadom kompresie dát. Neskôr, keď sa v roku 1949 začali popularizovať mainframy, Claude Shannon a Robert Fano vynašiel kódovanie, pomenované podľa autorov - Shannon-Fana. Toto šifrovanie priraďuje znakové kódy k radu dát teórie pravdepodobnosti.
Iba v sedemdesiatych rokoch minulého storočia, s príchodom internetu a online ukladaním, sa zaviedli plnohodnotné algoritmy kompresie. Huffmanove kódy sú dynamicky generované na základe vstupných informácií. Kľúčovým rozdielom medzi kódovaním Shannon-Fano a Huffmanovým kódovaním je to, že v prvom pravdepodobnostnom strome bol vytvorený zhora, vytvárajúci suboptimálny výsledok av druhom zhora nadol. V roku 1977 Abraham Lempel a Jacob Zev vydali svoju inovatívnu metódu LZ77 pomocou modernizovanejšej slovnej zásoby. V roku 1978 rovnaký tím autorov vydal vylepšený kompresný algoritmus LZ78. Kto používa nový slovník, analyzuje vstupné dáta a generuje statický slovník, nie dynamický, ako v 77verzia.
Formy kompresie
Kompresia sa vykonáva programom, ktorý používa vzorec alebo algoritmus, ktorý určuje, ako znížiť veľkosť dát. Predstavte si napríklad reťazec bitov s menším reťazcom 0 a 1 pomocou slovníka pre konverzie alebo vzorca. Kompresia môže byť jednoduchá. Napríklad, ako odstránenie všetkých nepotrebných znakov, vložením duplicitného kódu na označenie reťazca opakovania a nahradenie menšej bitovej mapy. Algoritmus kompresie súborov môže znížiť textový súbor až o 50% alebo oveľa viac. Pre prenos je proces vykonávaný v prenosovom bloku vrátane údajov hlavičky. Ak je informácie zaslané alebo prijaté cez internet, archív samostatne alebo spoločne s ďalšími veľkými súbory môžu byť prevedené ako ZIP, GZIP alebo iný "zmenšenej Výhodou kompresných algoritmov: ..
výrazne znižuje množstvo pamäte Ak je kompresný pomer 2: 1 súbor je 20 megabajtov (MB) trvá 10 MB priestoru. v dôsledku toho sieťoví administrátori strávia menej času a peňazí na databázach skladovanie.
Optimalizuje výkon zálohovania.
dôležitým spôsob zníženia dát. [14 ]
Virtuálne môže byť každý súbor napísaný ale je dôležité vybrať si požadovanú technológiu pre konkrétny typ súboru, inak by sa mohli znížiť, ale celková veľkosť sa nezmení.
Používajú sa dva typy metód - bezstratové a bezstratové kompresné algoritmy. Prvý z nich vám umožňuje obnoviť súbory do pôvodného stavu bez straty jednej bitovej informácie v komprimovanom súbore. Druhým je typický prístup kspustiteľné súbory, text a tabuľky, kde strata slov alebo čísel zmení informácie. Stláčanie strát trvale odstraňuje bity dát, ktoré sú nadbytočné, nedôležité alebo nepostrehnuteľné. Je to užitočné pre grafiku, zvuk, video a obrázky, kde odstránenie niektorých bitov prakticky nemá výrazný vplyv na prezentáciu obsahu.
Huffmanov algoritmus kompresie
Tento proces sa môže použiť na "zníženie" alebo šifrovanie. Je založený na cieľové kódy rôznej dĺžky z ktorých každý zodpovedá bit opakujúce sa charakter viac opakovaní, tým lepšie kompresný pomer. Ak chcete obnoviť zdrojový súbor, musíte poznať priradený kód a jeho dĺžku v bitoch. Podobne sa aplikácia používa na šifrovanie súborov. Postup pri vytváraní algoritmov pre kompresiu dát:
Vypočítajte, koľkokrát sa každý znak opakuje v súbore pre "redukciu".
Vytvorte prepojený zoznam s informáciami o symboloch a frekvenciách.
Vykoná triedenie zoznamu od najmenšieho k najväčšiemu v závislosti od frekvencie.
Preveďte každú položku v zozname na strom.
Skombinujte stromy do jedného, pričom prvé dva tvoria nový.
Pridá frekvencie každej vetvy na nový prvok stromu.
Vložte novú do požadovaného miesta v zozname podľa množstva prijatých frekvencií.
Priraďte nový binárny kód pre každý znak. Ak sa odoberie nulová vetva, do kódu sa pridá nula a ak je pridaná prvá vetva, jednotka sa pridá.
Súbor je zakódovanýzhody s novými kódmi.
, napríklad algoritmus vlastnosti kompresie krátkeho textu: "ata la Jaca la ESTACA"
sa počíta, koľkokrát je každý znak sa zdá predstavovať spájať zoznam: " ,
Poradie podľa frekvencie od najnižšej po vyššiu: e
,
,
) j
, s
, C
, l
, t
, " ,
Ako vidíte, vytvorí sa koreňový uzol stromu a potom sa priradia kódy.
a zostáva len baliť bitov v skupinách po ôsmich, ktorý je v bytoch:
, 01110010
, 11010101
11111011
, 00010010
, 11010101
, 11110111
(60 )
0xd5
0xFB
0x12
0xd5
0xF7
0xB9
0x80
Celkom osem bajtov, a zdrojový kód bol 23
knižnica Demonštrácia LZ77
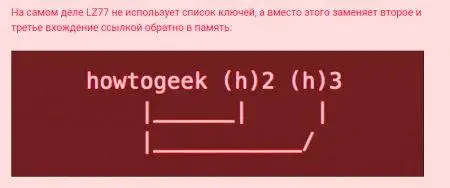
LZ77 algoritmus do úvahy príklad texte «howtogeek». Ak to zopakujete trikrát, zmení sa nasledovne.
Potom, keď si chce text prečítať späť, nahradí každú inštanciu (h) "howtogeek" a vráti sa k pôvodnej frázii. Ukazuje algoritmus kompresie bezstratových údajov, pretože vstupné dáta sú rovnaké ako prijaté dáta.
Toto je dokonalý príklad, keď je väčšina textu komprimovaná s niekoľkými znakmi. Napríklad slovo "to" bude krátka, a to aj v prípade, že sa vyskytuje v takých slovách ako "to", "to" a "to." S opakujúce sa slová môžu byť obrovské kompresný pomer.Napríklad text so slovom "howtogeek", zopakovaný 100-násobok veľkosti troch kilobajtov, s kompresiou bude trvať len 158 bajtov, to znamená s 95% "poklesom".
Toto je samozrejme skôr extrémny príklad, ale jasne ukazuje vlastnosti algoritmov kompresie. Vo všeobecnosti je to 30-40% textového formátu ZIP. Algoritmus LZ77 sa vzťahuje na všetky binárne dáta a nielen na text, hoci je ľahšie komprimovať opakovanými slovami.
Transformácia obrazu z diskrétneho kosínu
Kompresia video a audio funguje úplne inak. Na rozdiel od textu, ktorý vykonáva bezstratové algoritmy kompresie a dáta sa nestratia, obrazy sa "znížia" so stratami a čím viac%, tým viac strát. To vedie k hroznému vyzeraniu súborov JPEG, ktoré si ľudia niekoľkokrát sťahovali, vymieňali a robili screenshoty. Väčšina obrázkov, fotografií a ďalších ukladá zoznam čísel, z ktorých každý predstavuje jeden pixel. JPEG ich ukladá pomocou algoritmu kompresie obrázkov, ktorý sa nazýva diskrétna kosínová transformácia. Predstavuje súbor sínusových vĺn, ktoré pozostávajú z rôznych intenzít. Táto metóda používa 64 rôznych rovníc, potom Huffman kódovanie, na ďalšie zníženie veľkosti súboru. Podobný algoritmus kompresie obrazu poskytuje mimoriadne vysoký stupeň kompresie a znižuje ho z niekoľkých megabajtov na niekoľko kilobajtov v závislosti od požadovanej kvality. Väčšina fotografií je komprimovaná, aby ušetrila čas sťahovania, najmä pre mobilných používateľovzlý prenos údajov. Video pracuje trochu inak ako obrázok. Obvykle kompresné algoritmy grafiky s použitím toho, čo sa nazýva "interframe kompresie", ktorý počíta zmeny medzi každý snímok a uloží ich. Napríklad, ak je pomerne statický obrázok, ktorý trvá niekoľko sekúnd od videa, bude "znížený" na jeden. Interkom kompresia poskytuje digitálne televízne a webové video. Bez neho video vážilo stovky gigabajtov, čo je viac ako priemerný pevný disk v roku 2005. Kompresia zvuku funguje veľmi podobne ako kompresia textu a obrázkov. Ak máte odstrániť JPEG detaily obrazu, ktoré sú neviditeľné pre ľudské oko, pre kompresiu zvuku robí to isté pre zvuky. MP3 využíva prenosovú rýchlosť v rozmedzí od nižšej úrovne 48 a 96 kbit /s (dolná hranica), 128 a 240 kbit /s (celkom dobrý) až 320 kbit /s (vysoká kvalita zvuku) a počujete rozdiel môže byť len výnimočne dobrá slúchadlá. Existuje bezstratové kodeky pre audio, z ktorých hlavné je FLAC a používa kódovanie LZ77 pre prenos zvuku bez straty.
formáty "zníženie" textu
A radu knižníc pre texte sa skladá hlavne z kompresie dát bez straty, s výnimkou v extrémnych prípadoch, dáta s pohyblivou rádovou čiarkou. Väčšina kodekov kompresorové patrí "zníženie" LZ77 Huffmanova a aritmetické kódovanie. Používajú sa po ďalších nástrojoch na stlačenie niekoľkých ďalších percentuálnych bodov kompresie.
Spustite hodnoty zakódované ako znak, po ktorých nasleduje dĺžka spustenia. Môžete obnoviť výstup správnepotok. Ak je dĺžka série