Výber konkrétneho počtu záznamov z veľkého súboru je dobrý nápad, ale keď je súbor skutočne veľký, je to vplyv ponižovania nápadu. Výber viacerých položiek z určitej pozície vytvára skutočný pokles výkonnosti: pred dosiahnutím cieľa sa MySQL pozerá na ďalšie záznamy a trávi čas.
Limit MySQL môže formálne fungovať od začiatku tabuľky alebo od jej konca. Vzorkovanie môže určiť konkrétny počet vstupov začínajúcich z danej pozície. Tam môže byť vždy udalosť, to znamená, že nástup najhoršej situácie je možný. Zvyčajne celkový tok zákazníkov určuje všeobecný štatistický režim prevádzky, ale predpokladať, že sú potrebné rôzne situácie, je to vážne rozhodnutie v prospech lokality.
Konštrukčná syntax LIMIT
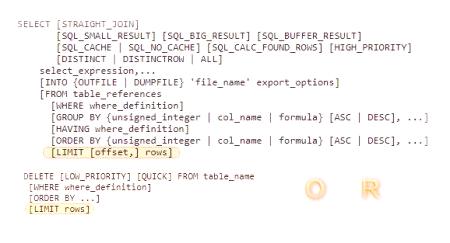
V oficiálnych zdrojoch je syntax obmedzenia MySQL označený ako zobrazený na obrázku nižšie v kontexte výberových a vymazávacích dotazov.
Žiadosť o výber vzorky (výber) zahŕňa dve čísla: offset "O" a "R", žiadosť o vymazanie je napísaná jedným číslom - počet záznamov "R" je vymazaný.
Veľké hodnoty limitu "O, R"
MySQL limit: syntax umožňuje výber hodnôt v akejkoľvek schéme. Základné podmienky: "O" je posun od prvého vybraného záznamu, "R" je počet vybratých záznamov. Problém je, že ak "O" = 9000, potom predtým, než MySQL vyberie záznam 9001, prejde prvými 9000. Ak je R = 1000, potom celková vzorka "bude mať" 10 000 záznamov. Limit výberu MySQL môže fungovať od začiatku tabuľky alebo od jej konca v závislosti od smeru triedenia záznamov asc /desc. Možnosť pracovať od koncaTabuľky nie sú sľubným riešením, aj keď v niektorých situáciách je ťažké to urobiť bez nej.
Design, kde veľký "R" by mal malý záujem pre vývojára a užívateľa: MySQL delete limit. A to je ďaleko od všetkých prípadov. V tomto návrhu hlavné bremeno zodpovednosti spočíva v stave vzorky (kde) vymazaných záznamov. Pre bezpečnosť a kontrolu procesu vymazávania záznamov sa vývojár obvykle zaujíma o použitie mechanizmu AJAX a nahrávanie záznamov v malých častiach. S takýmto mechanizmom si návštevník stránky nevšimne oneskorenia v návrhu odstránenia.
Ukážka podľa jedinečného záznamu
Správna podmienka, kde a okamžite spustí dotaz "limit 1" MySQL. Ale vymazanie alebo výber jednej položky nie je vždy dobré rozhodnutie. Zvyčajne sa na organizáciu údajov stránok (napríklad komentáre, články, recenzie produktov) používa prírastkový odber vzoriek pre všetky záznamy v tabuľke. Rozhodnutie o vytvorení obsahu webovej stránky by malo byť vykonané okamžite, ale s klasickým použitím limitu MySQL O, R bude rýchlo vybrať iba prvých desať z prvých sto záznamov, potom začne oneskorenie. Medzitým nie je všetko tak ťažké, môžete si rýchlo vybrať záznam, ale vyhrať kvôli návrhu a logike výstupu záznamu do prehliadača návštevníka.
Nič jej nebráni v tom, aby to urobilo veľkolepé a skrývalo fatálne oneskorenie v dialógu o tvorbe obsahu.
Vzťahové vzťahy v MySQL
MySQL je skvelý nástroj na prezentáciu a spracovanie informácií. Vývojár má dobrý dialekt jazykaSQL a vhodný mechanizmus na tvorbu dotazov. Chyby a nepredvídané situácie sú zaznamenávané, prístup k údajom je spravovaný až do úrovne základných operácií. Všetky nevýhody sa týkajú samotného konceptu vzťahov. Čo robiť, tento koncept funguje tak zásadne a spoľahlivo, niet čo robiť, ako zohľadniť jeho zvláštnosti a zohľadniť ich. Súčasná úroveň vývoja hardvéru, vysoko kvalitná implementácia funkčnosti všetkých nástrojov MySQL (limit nie je výnimkou) zabezpečuje dostupnosť veľkých objemov dát pri vysokých rýchlostiach a čo je najdôležitejšie, odber vzoriek.
Veľké objemy a štandardná vyrovnávacia pamäť
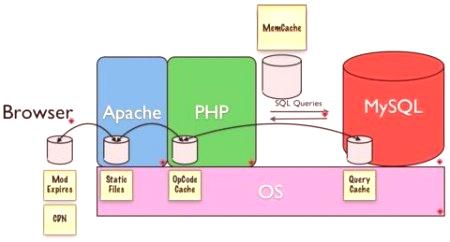
Buffering dáta pred záznamom a po odbere vzoriek - myšlienka je nádherná, má svoj pôvod od vzdialenej 80. rokov. Ukladanie do vyrovnávacej pamäte sa stalo módou na všetkých úrovniach spracovania dát od procesora, siete, samozrejme aj od úrovne servera http a skutočne databáz. Vývojár sa môže obrátiť na správcu servera alebo nakonfigurovať sám v cache na úrovni Apache a MySQL alebo inú kombináciu softvéru používaného na zabezpečenie prevádzky webového zdroja a servera MySQL.
Toto je normálne štandardné riešenie. Vo väčšine prípadov je to obvyklé. V programovaní je dlho hľadaná myšlienka rozdelenia práce. Vývojár robí stránky, správca spravuje prácu všetkého, čo poskytuje optimalizáciu využitia stránky. V kritických situáciách, keď databázové tabuľky sú veľké, sa musia odkloniť od prijatých kánonov. V dátovej organizácii musíte niečo zmeniť.
Tablichnapaging organizácie
Vývojári sú zvyknutí: relačné databázy - kolekcia tabuliek, ktoré sú vzájomne na klávesoch. Taká jednoduchá myšlienka, stôl predstavoval množstvo podobných stránok s rovnakým názvom, ale rôznych indexov, ktoré prekračujú obvyklý prezentáciu.
Ale čo je tu smiešne? Tabuľka je súbor záznamov obsahujúcich rôzne údaje, ktoré zodpovedajú typom polí (stĺpcov, hlavičiek tabuliek). Požiadavka MySQL Limit dotazu odkazuje na tabuľku "big_info" a zvolí c 100000 polohách 24 zobrazenie riadku v prehliadači. V tomto rozhodnutí sa do vzorky zúčastnilo 100024 riadkov - je to dlhá doba. Ale ak zmeniť situáciu a celý stôl "big_info" maľovať niekoľko sto tabuľky "big_info [0999]" 1000 záznamov, problém nastáva len vtedy, keď budete vyzvaní MySQL "objednávku * hraničné O, R", pretože triedenie bude mimoriadne ťažké. Avšak, a to nielen triediť, ale akékoľvek iné transakčné záznamy o všetkých dostupných prostriedkov nemožné databázovú tabuľku vyššie, ktorý je reprezentovaný niekoľkých tabuliek. V tomto kontexte nie je žiadny index v MySQL. Vzťahové vzťahy poskytujú jasnosť: existuje databáza, má tabuľky, tabuľky - stĺpce a záznamy. No, existujú "lotion": uložené procedúry, triggery, podmienky a ďalšie podrobnosti.
Vlastné pamäť a prostriedky k
dobrý nápad, "Yandex" - "tepelné": teplotné mapa na web. Tento nástroj zobrazuje v rozhodnutí o spektrálnej farbe rozloženie relevancie návštevníkov na "územie" stránky. Zrejme sa čoskoro objaví nový predmet - geografia webovej stránky: kde a kam umiestniť. Dobrý prírastok k generálovigeografia Táto myšlienka, preložená na územie záznamov veľkých tabuliek databázy, nám umožňuje formulovať objektívnu tézu: nie celé územie záznamov je dopytované a nie vždy.
Čím väčší je tok návštevníkov, tým viac súhlasí s potrebami vzorky. Limit MySQL je vždy vykonávaný presne a vždy z určitého dôvodu. Zhromažďovanie konkrétnych dôvodov nikdy nebude fungovať. Z každého konkrétneho dôvodu sú výsledkom MySQL limitov v každom prípade triviálne. Ukazuje sa, že nie je tabuľka organizácie stránok vo formáte stoviek podobných stránok a kužeľ požiadavky na informácie. Len vo smrteľných prípadoch alebo pri vstupe na stránku informatívneho návštevníka je vzorka veľkého množstva údajov. Bežne sa vyberú čipy. Vlastná vyrovnávacia pamäť elementárne rieši problém rýchlosti: vzorka prejde na kľúč "špecifická príčina" z malého stola výsledkov nedávnych operácií vzorky z jedného veľkého stola.
Triedenie a iné veľkoobchodné operácie
Problém veľkých objemov dát spočíva vo vykonávaní hardvérového softvéru. Dnes sa dosiahla obrovská úroveň výkonnosti, ale objemy údajov tiež výrazne vzrástli. Pri zvyšovaní rýchlosti a kvality ciest sa adekvátne zvyšuje potreba rýchleho pohybu a okamžitého riešenia úloh. Jednoduchá operácia triedenia, písania alebo vyhľadávania ovplyvňuje priamo alebo nepriamo všetky záznamy veľkého stola - potenciálnu brzdu, garantovanú stratu výkonu.
Relačnývzťah bol príliš dlhý na dlaň majstrovstiev, ale dávať cestu tomuto dňu nemajú v úmysle: len nikomu. Iné varianty organizácie dát, ktoré poskytujú okamžitú navigáciu na veľkom množstve informácií, dokonca ani neprichádzali so super-leaderom priemyslu "Great Information" - Oracle. Ale spoločnosť Oracle poskytuje dobré skúsenosti a vynikajúce znalosti v implementácii jazyka SQL a jeho dialektov. Vo funkcii MySQL má istý odtlačok kvality. Vývojár môže bezpečne používať návrh limitu MySQL na jednu dátovú tabuľku a má voľný prístup k veľkoobchodným operáciám nad touto veľkou tabuľkou.
Prirodzené vnímanie informácií
Človek vníma a spracováva, väčšinou nevedomky, obrovské množstvo informácií, ktoré nie sú k dispozícii pre najpokročilejšie nástroje od spoločnosti Oracle. Ale na to nemôže byť obzvlášť hrdý. Spoločnosť Oracle dokáže migrovať takýto objem údajov a vykonať takéto triedenie, čo vyžaduje viac ako sto prípadov ľudského života.
Každý musí robiť svoju prácu a robiť to najefektívnejším spôsobom. Vzťahové postoje nikdy nebudú vymazané - sú osobitné pre dáta, sú ich neoddeliteľnou súčasťou. Implementácia databáz v relačných vzťahoch však nemá sémantiku. Kľúčovou organizáciou, indexy prístupu k záznamom, nie je obsah, ktorý poskytuje rýchly prístup k informáciám. Konzistentná organizácia pamäte počítača a emulácia asociačného prístupu k informáciám - skutočný dôvod na stratu času pri prístupe k veľkému stolu na odber vzorky informácií pri dodržiavaníintegrita pre skupinové operácie.
informačné objekty a prírodné združenia
, aby sa zabránilo vykonávanie operácií, kým developer nemôže. Tak usporiadaný počítačový svet. Počítač má procesor a multi-core a viacprocesorových verzia - nie je to neurálnej usporiadanie paralelného spracovania informácií použitých ľudskej mysle. Vývoj algoritmu vždy apeluje na jeden proces, aj keď rozdelený do mnohých prúdov. Programovanie, kým je na rovnakej úrovni, a to aj keď je kód vytvorený vo forme systému interagujúcich objektov, kópia, ktorá pôsobí na ich vlastné. Otázkou je, nie toľko ako na štruktúru informačných systémov ako samostatné objekty, ale v prostredí, ktoré zabezpečí ich fungovanie. Streda je konzistentná, nie paralelná. Zvýšenie počtu jadier a počet procesorov v počítači, tablete alebo iného zariadenia, neznamená, že je asociatívne výpočtové zariadenia.
Ale výstup je stále tam: každá konkrétna aplikácia je problém, na ktorý potrebujete nájsť rýchlu odpoveď. Je potrebné vykonať rýchlu voľbu (MySQL limitnou) napriek skutočnosti, že ďalšie funkcie (MySQL objednávku, skupinu, Pripojiť & amp; kde) nebude ovplyvnená, tabuľka bude rozdelená do mnohých rovnakých dielov a medzipamäte postup bude dostávať aktualizácie hneď po aktualizácii , a nie keď dostanú iný "špecifický dôvod". Jazyk SQL je dobrý jazyk, ale ak pridáte asociácie, bude to ešte lepšie.