technológia OCR (Optical Character Recognition) možno previesť papierové dokumenty do elektronickej verzii. Napríklad, ak skenujete viacstránkové kopírovanie súborov TIFF, je načítaný do OCR-program, ktorý rozpozná text a potom prevedený na upraviteľný súbor. Niektoré programy vám umožňujú skenovať stránky a konvertovať obsah do dokumentu v jednom kroku. Aj keď technológia bola pôvodne vyvinutá pre optické rozpoznávanie tlačených znakov, môže byť tiež použitá pre rukopisu. Napríklad, poštové služby, ako je USPS, pomocou OCR softvér pre automatické spracovanie poštových zásielok a balíkov, čítanie adresu.
Oblasti použitia OCR
OCR je dekódovaný ako optické rozpoznávanie znakov. Táto technológia je široko rozpoznať text v obrázkoch sú naskenovaných dokumentov a fotografií. Použitá technológia pre prevod takmer všetky typy obrázkov, ktoré obsahujú písomné, ručne písaný alebo tlačený text do počítačovo čitateľných textových dát.
OCR stala populárnou v skorých 1990 pri pokuse o digitalizácii historických materiálov. Od tej doby sa táto metóda prešla významné vylepšenia a teraz poskytuje takmer dokonalú presnosť OCR. Pokročilé techniky, ako Zonal OCR, sa používajú na automatizáciu zložitých pracovných postupov založených nakonverziu zadaných textov na digitálne dokumenty. Akonáhle naskenované materiálne procesy prostredníctvom textu možno upraviť s použitím programov, ako je Microsoft Word alebo Google Docs, ktoré sú textové editory. Predtým, než táto technológia bola jediná možnosť pre digitalizáciu tlačených dokumentov bol ručné písanie. Nielenže ma to veľa času, ale tiež viedla k nepresnostiam a chybám pri prehrávaní kópiu. OCR je často používaný ako "skrytý" technológie v mnohých známych systémov a služieb, vrátane automatizovaného zadávanie dát a indexovanie pre vyhľadávače, automatické optické rozpoznávanie znakov štátnych poznávacích značiek, rovnako ako pomoc nevidiacim a zrakovo postihnutým ľuďom.
Spôsob stanovenia presnosti textu
Každý krok procesu OCR je dôležitý na určenie presnosti konečného textu. Začína konverziou vytlačeného dokumentu. Ak tam sú stopy, škvrny a zlý kontrast, pri detekcii softvér bude robiť chyby, a výsledok bude nesprávna. Ak sa chcete vyhnúť týmto problémom, môžete vylepšiť fotokópiu. Prvým krokom práce je skenovanie vytlačeného textu. Softvér OCR pracuje so súbormi obrázkov. Skener alebo dobrý digitálny fotoaparát vytvára jasné fotokópie dokumentov. Je lepšie konvertovať skenované súbory čierne a biele. Proces je binárny. Čierna farba v obraze rozpozná rozpoznávanie textu OCR a biela zase pôsobí ako pozadie. Druhá fáza jedefiníciu znakov Rýchlosť tohto procesu závisí od programu OCR, ktorý používate. Väčšina z nich analyzuje každý prvok jeden po druhom. Cieľom je určiť ukazovatele, ale dobré programy uznávajú nielen text, ale aj tabuľky a ďalšie prvky rozvrhnutie. Proces nie je dokonalý, pretože existuje veľa faktorov, ktoré ovplyvňujú presnosť. Aké programy sú určené na optické rozpoznávanie znakov, zvážime nižšie. A užívateľ si môže slobodne vybrať to, čo je najlepšie. OCR majú zabudované funkcie na kontrolu pravopisu a zdôrazňujú zavádzajúce slová. Niektoré z nich sú tak zložité, že poznámka rozpor slov a gramatických chýb, môže užívateľ vykonávať iba nevyhnutné úpravy. Posledným krokom je uloženie dokončeného dokumentu v správnom formáte. Ak to aplikácia nevyžaduje, môžete využiť množstvo bezplatných online konvektorov.
Optická technológia pre Braillovo písmo
Technológia optického rozpoznávania znakov (OCR) umožňuje nevidiacim alebo zrakovo postihnutým ľuďom identifikovať telo a vysloviť to nahlas. Toto používa jazykový výstup a zobrazuje informácie na braillovom displeji. Existujú tri hlavné prvky systému optického rozpoznávania znakov: získanie obrazu, rozpoznávanie a čítanie textu. Pôvodne tlačený dokument kamera je zachytený, potom softvér OCR prevádza ho na uznávané znaky a slová, a potom syntetizátor systém vysloví nahlas nejaký materiál, alebo sa zobrazí na displeji Braillovho písma. Informácie môžuuložené elektronicky na zariadení so softvérom OCR alebo v samostatnej pamäti zariadenia. Proces zohľadňuje logickú štruktúru jazyka. Systém skonštatuje, že napríklad "toto" na začiatku návrhu je chybou a malo by sa to chápať ako "toto". Používa slovnú zásobu a používa verifikačné metódy podobné tým, ktoré používajú v mnohých textových editorech. Všetky systémy OCR vytvárajú dočasné súbory, ktoré obsahujú znaky a rozloženia stránok. Na niektorých systémoch je možné ich previesť na formáty, ktoré možno nájsť pomocou bežne používaných počítačových aplikácií, ako je textový editor, tabuľkový procesor a databázy.
Výber programov na rozpoznávanie textu
Odporúča sa, aby ste zámerne pristupovali k výberu softvéru na rozpoznávanie textu. Najlepšie je otestovať alebo zohľadniť názor pokročilých používateľov. Testovanie sa vykonáva s prihliadnutím na tieto faktory:
Presnosť je to, čo rozlišuje dobrý OCR od zlého. Je však nereálne očakávať 100% presnosť programu rozpoznávania rukopisu. Faktory, ako kvalita originálnych dokumentov a rozlíšenie obrazu, významne ovplyvňujú výsledok. Dobré OCR dosiahnu 98%, ak používate moderný skener a zdrojový kód v uspokojivom stave.
Viacjazyčnosť - Dnes je táto funkcia vo väčšine programov. OCR naskenuje samostatný znak, ktorý ho identifikuje. Ak je určený na rozpoznávanie iba anglických písmen, potom to nebude možnépresne vykladať špeciálne znaky, napríklad písmená ako písmená s dôrazom na "e". To bude znamenať tieto znaky s najbližším ekvivalentom v angličtine. Pri aplikácii, ktorá podporuje viacjazyčnosť, je špecifikovaný jazyk dokumentu, ktorý zabezpečí presnosť rozpoznávania.
Podpora rukopisu. Text vytvorený pomocou klávesnice je ľahko rozpoznaný ľubovoľným programom. Ručne písaný je úplne iný spôsob skenovania. Ľudia majú veľmi odlišný rukopis. Niektorí píšu úhľadne, zatiaľ čo väčšina rukopisu nie je dostatočne čitateľná. Kvalitatívne OCR dokážu rozpoznať akýkoľvek rukopis. Preto chcete archivovať ručne písaný materiál, potrebujete programy na ručné písanie.
Úroveň automatizácie. OCR možno spustiť automaticky alebo interaktívne. Ak potrebujete skenovať viac stránok naraz, najlepšie je zvážiť automatické programy. Pomocou tejto funkcie môžete skenovať dokumenty s niekoľkými kliknutiami pri vykonávaní ďalších úloh a je ľahké nájsť výsledný súbor PDF, txt alebo doc. Väčšina programov na rozpoznávanie textu má obmedzenú automatizáciu.
Zachovanie rozloženia. Hlavným účelom týchto programov je preklad textu do elektronickej podoby. Niektoré z nich nezachovávajú rozloženie pôvodného dokumentu. Preto je potrebné dlho upraviť finálnu verziu. Dobrý program by mal zachrániť pôvodné rozloženie a v konečnej kópii je potrebná menšia kópia. Takéto programy ukladajú stĺpce tabuliek a grafické obrázky, ako v pôvodnej verzii.
Populárny mobilný softvér
OCR je skvelý nástroj na prenos textu z fyzických zdrojov priamo do digitálneho dokumentu. Existujú rôzne typy aplikácií a aplikácií pre stolné aj mobilné zariadenia. Sú rozdielne v cene a majú svoje vlastné kľúčové vlastnosti.
Najobľúbenejšie skenery Android:
Office Lens - Poskytuje bezplatnú skenovanie stránok a OCR pre užívateľov Android. Ak chcete konvertovať, musíte sa pripojiť k internetu.
Skenery PDF (napríklad ABBYY TextGrabber, CamScanner, MDScan, OCR Instantly) - vykonajte skenovanie s následným OCR. Počet naskenovaných stránok a žiadne vodoznaky nie sú obmedzené.
Online OCR. Môžete ho nájsť na internete, služba je veľmi jednoduchá a ľahko sa používa. Charakteristickou vlastnosťou je, že podporuje 46 jazykov, výstupný dokument váži nie viac ako 5 MB, ľahko sa prevádza do formátu Microsoft Word, Excel alebo vo formáte obyčajného textu. Po registrácii môžete previesť viacstranové PDF, RTF, Excel a súbory do 100 MB. Pri veľkých počtoch rozpoznávania je platenú verziu.
Dokumenty Google
Pre tých, ktorí už poznajú dokumenty Google, môžete použiť nástroj OCR zabudovaný do služby Disk Google. Ak chcete dosiahnuť najlepšie výsledky, písmo musí byť nastavené na Arial alebo Times New Roman. Výsledok môžete zlepšiť tým, že skenovaný obrázok má dokonca svetlý a jasný kontrast. Fotografické materiály je možné spracovať samostatne v jpg, png, gif alebo vo viacstranových dokumentoch PDF. Rozšírenie podporuje väčšinu jazykov. Google má veľa tréningových programov a schopností spracovania cloud. Mnohí používatelia sa domnievajú, že služba nemá pokročilé funkcie a možnosti. Ak však používate aplikáciu Disk Google pre Android, môžete skenovať stránky priamo z aplikácie pomocou fotoaparátu na vašom smartfóne. V opačnom prípade stiahnite dokumenty pomocou skenera pripojeného k počítaču alebo akýmkoľvek iným spôsobom spustite rozpoznávanie spracovania v službe Disk Google. Pre jednotlivcov ponúka Disk Google bezplatnú úroveň ukladacieho priestoru približne 19 GB s možnosťou rozšírenia až o 100 GB prostredníctvom služby Google One za 199 EUR. US.
Optické rozpoznávanie Abbyy
Abbyy FineReader dlhodobo pracuje s dokumentmi. Je to komplexné riešenie pre obchodných aj bežných používateľov. Umožňuje vám získať všetky potrebné funkcie na extrakciu obsahu textov z čítačky v plnom rozsahu, úhľadne organizovaných digitalizovaných materiálov. Okrem rozpoznávania a konvertovania textu do formátu PDF, Microsoft Office alebo iných formátov môže program porovnávať ich, pridávať anotácie a komentáre. Abbyy FineReader dokáže konvertovať materiál v dávkovom režime a spracovať veľa výstupných formátov v 192 rôznych jazykoch. K dispozícii sú sprievodné mobilné aplikácie, keď potrebujete vykonať rýchlu kontrolu z telefónu. Softvér nie je aktuálny, ale je jednoduchý, funkčný a pracuje dobre s jeho prácou. Pomôcka má pevnú reputáciu ako jednu z najlepších možností v oblasti optického rozpoznávania znakov. Môžete použiť bezplatnú skúšobnú verziu. Za náklady z19999 dolárov USA na štandardnú jednotnú perpetuálnu licenciu. Ak sa zdá, že niekto je drahá možnosť, môžete mať dobrú alternatívu k ABBYY FineReader - on-line verzii. Je obmedzený na skenovanie iba 10 strán za mesiac. Ale prichádza so všetkými ostatnými prémiovými funkciami. Na získanie prístupu sa musíte zaregistrovať. Podporuje veľa formátov vstupných súborov a môžete si vybrať výstupné súbory ako sú PDF, Word, Excel, PowerPoint a e-Pub.
Služba Cloud Acrobat
Aplikácia Adobe Acrobat spĺňa všetky požiadavky a ponúka pôsobivý zoznam funkcií a možností, aj keď cena je o niečo strmšia ako konkurencia. Pre všetky funkcie rozpoznávania optického textu vyberte verziu Pro programu Adobe Acrobat. DC znamená "Dokument Cloud" a úplne jasne integruje riešenie Adobe pre cloud, ak chcete získať prístup k súborom z ľubovoľného počítača. Jednoduchá a bezproblémová integrácia so všetkými ostatnými službami Adobe, ako napríklad Photoshop. Ak sa užívateľ rozhodne platiť za Pre verziu Adobe Acrobat, DC, bude mu získať všetky nástroje OCR, možnosť pridávať komentáre a spätnú väzbu k obsahu, špecializované služby pre skenovanie tabuliek rýchle porovnanie týchto dvoch dokumentov dohromady. Materiály je možné upraviť priamo na obrazovke niekoľko sekúnd po ich naskenovaní. Adobe Hviezda zaručuje určitú úroveň kvality, a užívatelia sú ohromení a intuitívne schopnosti Adobe Acrobat DC. Predplatné služby začína na úrovni 1.299 USD. US.
Najlepšie Free Software
Voľný OCR to Word je najlepší freewareOptický softvér na rozpoznávanie znakov pomocou najnovších mechanizmov. Tesseract je najsilnejší nástroj pre tento typ a považuje sa za jednu z najpresnejších metód. Program podporuje viaceré formáty obrázkov a TIFF viacerých stránok. Táto služba môže byť úplne bezplatná na extrahovanie textu z poskytnutého fotografického materiálu. Motor Tesseract bol pôvodne vyvinutý firmou Hewlett Packard Labs v rokoch 1985-1994. Niektoré zmeny mu boli vykonané v roku 1996. V roku 1995 bol zaradený do prvých troch uznaných mechanizmov. Pracuje s operačnými systémami Windows, Linux a Mac OS X. FreeOCR dokáže pracovať s obrázkami, ktoré majú viacjazyčný a viacjazyčný text. Spravuje formáty PDF a podporuje zariadenia TWAIN, ako sú skenery, má rozšírené rozhranie s dvoma oknami, ktoré je ľahké pochopiť.
Voľný OCR do programu Word môže ušetriť veľa času bez toho, aby ste museli znova zadávať prácu, ktorú ste už napísali. Program zaberie dokument, naskenovaný objekt alebo obrázok a prevedie ho na čitateľný, editovateľný a presný materiál. Môžete si ho zadarmo stiahnuť v programe Word. Program OCR to Word je optimalizovaný pre prácu so všetkými typmi skenerov a má presnosť 98%, moderné rozhranie, ktoré umožňuje jednoduchý prístup k všetkým úlohám, v prípade, že sa fotografie na obrazovke nezhoduje správne, sú funkcie otočenia. FOR extrahuje text z nasnímaných obrázkov pomocou smartphonov alebo digitálnych fotoaparátov s vysokou presnosťou a kvalitou.
Rozpoznávanie znakov v systéme Linux
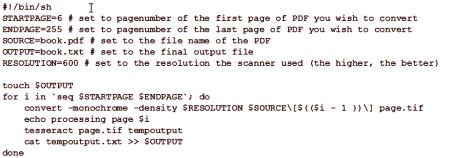
Sada OCRFeeder poskytuje pohodlné grafické používateľské rozhranie pre systém Linux.čo je v podstate externé rozhranie pre niektoré obrázky, OCR a textové nástroje, ako je tlač alebo kontrola pravopisu. Samotné znaky nečaká, ale používa iné programy OCR prostredníctvom tzv. "Mechanizmov rozpoznávania". Má určité parametre pre Tesseract, CuneiForm, GOCR a Ocrad. Užívateľ potrebuje iba nainštalovať do Ubuntu motory, ktoré si vyberie - jeden alebo viac a potom ich zistiť v nastaveniach podávača. Môžete pridať ďalšie motory a upraviť tieto nastavenia manuálne. V jednej aplikácii môže byť niekoľko rôznych motorov. V hlavnom okne podávača môžete počas letu vybrať, ktorý z nich má byť použitý pre konkrétny priemysel, je tiež predvolené nastavenie. Ak chcete vybrať jazyk textu čítania, v prípade Tesseract a klinového písma, musíte pridať prepínač «-l» s príslušnou jazykovou kódu /skriptu, napríklad, «-l pol» na poľskom alebo «-l dan-frak» dánskych nastavenie motora Technológia optického rozpoznávania tlačených znakov "Tesseract" na začiatku dokázala rozpoznať text v angličtine, verzia 2.x to urobila viacjazyčnou. V prípade potreby môžete nainštalovať viac ako jeden slovník. Nové verzie digitalizujú text podľa ISO 963-2. Po úspešnej inštalácii použite príkaz "tesseract & gt; image path & gt; základný názov výstupného súboru". Tesseract automaticky pridá zdrojový súbor s príponou .txt, môžete zadať voľbu -l a kód jazyka. Pre verzie programu Tesseract skôr ako tretie, je veľmi dôležité, aby mal obrázok vo formáte súboru značiekrozšírenie ".tif", nie ".tiff". Príkazový riadok by mal vyzerať takto: "$ tesseract ~ /input.tif output". Kde "input.tif" je transformačný dokument umiestnený v domovskom priečinku a "output" je materiál, ktorý Tesseract vytvorí ako "output.txt". Často naskenované texty sú uložené ako rastrový obrázok vo veľkom dokumente PDF. Pomocou aplikácie ImageMagick je možné jednotlivé stránky vytlačiť ako súbory TIFF na spracovanie od spoločnosti Tesseract. Nasledujúci skript vám pomôže automatizovať tento proces.
Program CuneiForm je ďalší systém na rozpoznávanie textu, ktorý bol pôvodne vyvinutý a založený na open source Cognitive Technologies. Verzia systému Windows, ktorá má vlastné grafické rozhranie, môže byť spustená s niektorými výsledkami vo víne. Jeho Linuxový port sa vyvíja na Launchpade a hoci v súčasnosti nemá vlastné grafické rozhranie, CuneiForm môže byť úspešne spustený z grafického rozhrania OCRFeeder. Nižšie je uvedený príklad toho, ako úspešne previesť niektoré obrazovky obrázkov bulletinu .jpeg do užitočných textových súborov online.
Pdfocr je skript, ktorý spúšťa OCR pre viacstranové súbory PDF, ako aj implementuje ho ako vyhľadávaciu textovú vrstvu. Môže používať Tesseract alebo klinček ako mechanizmus rozpoznávania. Samotný scenár je možné získať od spoločnosti Github alebo PPA. Ak chcete spustiť príkaz, napíšte do terminálu: "pdfocr -i input.pdf -o output.pdf". Technológia OCR nezostáva stáť, v dlhodobom horizonte rozpoznáva intelektuálny systém optického rozpoznávania znakov - ICR. Tento štandard je pokročilý. skvelýčasť ICR má systém vlastného vzdelávania nazývaný neurónová sieť, ktorá automaticky aktualizuje databázu nových vzorov rukopisu. Rozširuje užitočnosť skenovacích zariadení na účely spracovania dokumentov od rozpoznávania tlačeného textu (funkcia OCR) na ručne písané materiály a pri čítaní rukopisného materiálu v štruktúrovaných formách môže dosiahnuť presnosť viac ako 97%.