Kódovaním informácií v počítači odkazuje na proces transformácie do formy, ktorá umožňuje organizáciu pohodlnejšieho prenosu, ukladania alebo automatického spracovania týchto údajov. Na tento účel sa používajú rôzne tabuľky. Kódovanie ASCII je prvý systém vyvinutý v Spojených štátoch pre prácu s anglickým textom, ktorý bol následne distribuovaný na celom svete. Jeho opis, funkcie, vlastnosti a následné použitie výrobku je uvedené nižšie.
Displej a uchovávať informácie v počítači
Symboly na obrazovke počítača alebo konkrétny mobilný digitálny gadgets sú založené na rôznych sád vektorových tvarov značenie kód, ktorý vám umožní nájsť medzi nimi aj znak, ktorý chcete vložiť potrebujeme miesto. Je to postupnosť bitov. Preto musí každý znak zodpovedať množine núl a jednotiek, ktoré sú v určitom, jedinečnom poradí.
Ako to všetko začalo
Historicky boli prvé počítače anglicky hovoriaci. Na kódovanie informácií o znakoch v nich stačilo používať iba 7 bitov pamäte, zatiaľ čo na tento účel pridelené 1 bajt, ktorý pozostáva z 8 bitov. Počet znakov, ktoré počítač v tomto prípade pochopil, bol iba 128. Tieto znaky pozostávali z anglickej abecedy s interpunkčnými znakmi, číslami a niektorými špeciálnymi znakmi. Sedembitové kódovanie v angličtine s príslušnou tabuľkou (kódová stránka), vyvinuté v roku 1963, bolo označené ako Americký štandardný kód pre informácieInterchange. Typicky sa používa skratka "ASCII kódovanie", ktorá sa používa na označenie.
Prechod na viacjazyčnosť
Počítače sa časom vo veľkej miere používajú v neanglicky hovoriacich krajinách. V súvislosti s tým vznikla potreba kódovania, ktorá by umožňovala používanie národných jazykov. Bolo rozhodnuté, že nebudeme objavovať motocykel a založiť ASCII. Kódujúca tabuľka v novom vydaní sa výrazne rozšírila. Pomocou 8. bitu môžete preložiť 256 znakov do počítačového jazyka.
Opis
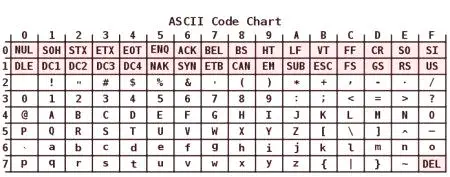
Kódovanie ASCII má tabuľku, ktorá je rozdelená na 2 časti. Všeobecne uznávaná medzinárodná norma sa považuje za prvú polovicu. To zahŕňa :.
znakov so sériovým číslom od 0 do 31 kódovaných sekvencií od 00000000 do 00011111. sú vyhradené pre riadiace znaky, ktoré kontrolujú proces odstraňovania text na obrazovke alebo porciu tlačiarne, zvuku a tak ďalej P. Symboly NN v tabuľke od 32 do 127 kódovaných sekvencií od 00100000 do 01111111 tvoria štandardnú časť tabuľky. Patrí medzi ne priestor (N 32), pričom písmená abecedy (veľké a malé), desaťmiestne číslo od 0 do 9, interpunkčné znamienka, zátvorky rôznych tvarov a ďalších symbolov., znaky s poradovými číslami od 128 do 255 kódovaných sekvencií od 10000000 do 11111111. Patrili k nim písmená národných abecied iných ako latinčina. Ide o alternatívnu tabuľka kódovanie ASCII sa používa na prevedenie počítačovej formulára ruskej znaky.Niektoré vlastnosti
Zvláštne funkcie zahŕňajú kódovania ASCII na rozdiel od písmena "A" - «Z» dolné a horné registre iba jeden bit. Táto okolnosť značne zjednodušuje transformáciu registra, ako aj jeho overenie, že patrí k danému rozsahu hodnôt. Okrem toho sú všetky znaky v ASCII kódovaní systemis predstavili svoje vlastné sériové čísla v abecede, napísal päť čísel v dvojkovej sústave, na ktoré sa malé písmená v hodnote 011 2, a horná - 010 2.
Medzi znaky kódovania ASCII môžete počítať prezentáciu 10 číslic - "0" - "9". V druhom systéme začínajú 00112 a končia 2 hodnotami čísel. Áno, 0101 2 desyatychnomu ekvivalentné číslo päť ako symbol "5" je písaný ako 001101012. Na základe vyššie uvedeného, je ľahké previesť binárne desatinné čísla v ASCII kódovaného reťazca pridaním sekvencie bitov zľava každej polubaytu 00112.
"Unicode"
Je známe, na zobrazenie textu v jazykoch, skupiny z juhovýchodnej Ázie je potrebné tisíce znakov. Nejedná sa o číslo je popísané v jeden bajt informácií, takže aj predĺžená verzia ASCII nemohla uspokojiť rastúce potreby užívateľov z rôznych krajín.
To znamená, že je potrebné vytvoriť univerzálny kódovanie, ktorá sa vyvíja v spolupráci s mnohými svetovými vodcami zaoberajúcich sa IT priemysel konzorcium Unicode. Jeho špecialisti vytvorili systém UTF 32. V ňom kódovať 1 znak pridelených 32 bitov, pozostávajúci zo 4 bajtov informácií. Hlavná vecNevýhodou bolo prudké zvýšenie množstva pamäte, ktoré bolo potrebné až štyrikrát, čo znamenalo veľa problémov. Zároveň je pre väčšinu krajín s úradnými jazykmi patriacimi do indoeurópskej skupiny počet známok rovnajúci sa 2 32 viac ako prebytok. Vďaka ďalšej práci odborníkov z konzorcia Unicode sa objavilo kódovanie UTF-16. Stala sa možnosťou premeny symbolických informácií, ktoré skomponovali všetko množstvo požadovanej pamäte a počet zakódovaných znakov. Z tohto dôvodu bol štandardne prijatý UTF-16 a v tomto prípade pre jeden znak je potrebné rezervovať 2 bajty. Aj táto pomerne pokroková a úspešná verzia Unicode mala niektoré nevýhody a po prepnutí z rozšírenej verzie ASCII na UTF-16 bola hmotnosť dokumentu zdvojnásobená. V tomto ohľade bolo rozhodnuté používať kódovanie UTF-8 s premennou dĺžkou. V tomto prípade je každý symbol zdrojového textu zakódovaný v sekvencii s dĺžkou 1 až 6 bajtov.

Odkaz na americký štandardný kód pre výmenu informácií
Všetky znaky v latinke v UTF-8 variabilnej dĺžky sú zakódované v 1 bajte ako v systéme kódovania ASCII. Funkciou UTF-8 je, že ak je text v latinčine bez použitia iných znakov, dokonca aj programy, ktoré nerozumejú Unicode, jej stále umožňujú čítať. Inými slovami, základná časť kódovania ASCII textu jednoducho prechádza do novej variabilnej dĺžky UTF. Cyrilické znaky v UTF-8 zaberajú 2 bajty a napríklad gruzínsky - 3 bajty. Vytvorenie UTF-16 a 8 vyriešilo hlavný problém vytvorenia jediného kódu v písme. sOdvtedy môžu výrobcovia fontov vyplňovať tabuľku len s vektorovými textovými znakmi založenými na ich potrebách.
Rôzne operačné systémy dávajú prednosť rôznym kódovaniam. Aby bolo možné čítať a upravovať texty napísané v inom kódovaní, používajú sa programy transkódovania ruského textu. Niektoré textové editory obsahujú zabudované enkodéry a umožňujú vám čítať text bez ohľadu na kódovanie.
Teraz viete, koľko znakov v kódovaní ASCII a ako a prečo boli vyvinuté. Samozrejme, dnes najrozšírenejší na svete získal štandard Unicode. Nesmieme však zabúdať, že je založené na ASCII, takže hodnota jeho vývojárov v oblasti IT by sa mala náležite zhodnotiť.