Po kurzoch SEO propagácie, nováčikovia stretnúť s mnohými zrejmých a nepríliš podmienok. Skrz tento obchod nie je tak jednoduché, najmä ak dôjde k strate alebo zle vysvetlil niektoré z otázok. Zoberme si hodnotu v súbore robots.txt Disallow, čo robí tento dokument, ako vytvoriť a pracovať s ním.
V jednoduchých slov
"kŕmiť" Čitateľ komplikované vysvetlenie, ktoré sa bežne vyskytujú na špecializovaných stránkach, aby lepšie vysvetliť všetky "prsty". Vyhľadávací robot príde na vaše stránky a index stránok. Keď vidíte správy, ktoré označujú problémy, chyby a iné
, ale web, a táto informácia sa nevyžaduje pre štatistiku. Napríklad na stránke "Výpisy" alebo "Kontakty". Toto nie je nutné pre indexovanie a v niektorých prípadoch nežiaduce, pretože to môže narušiť štatistiku. Že to nie je len lepšie zavrieť stránkami práce. To je pre tento tím a potrebujeme súboru robots.txt Disallow.
Štandardná
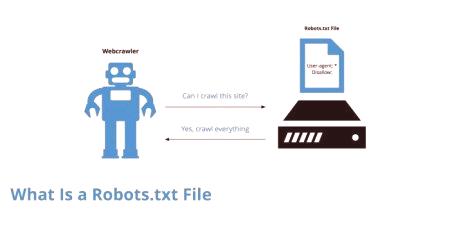
Tento dokument je vždy k dispozícii na internetových stránkach. Jeho tvorba zapojená vývojárov a programátorov. Niekedy to môže robiť a vlastníci zdrojov, najmä v prípade, že je malý. V tomto prípade je dielo nemusí trvať dlho. Robots.txt volal štandardné vylučovať roboty. On predložila dokument, v ktorom hlavné predpísané limity. Dokument je umiestnený v koreňovom adresári prostriedku. V rovnakej dobe, aby mohol nájsť spôsob, ako «/robots.txt». akzdroj má niekoľko subdomén, potom je tento súbor umiestnený v koreňovom adresári každého z nich. Štandard je nepretržite prepojený s iným - súbory Sitemap.
Mapa stránok
Pre pochopenie úplného obrazu toho, o čom sa diskutuje, niekoľko slov o súboroch Sitemap. Toto je súbor napísaný v jazyku XML. Ukladá všetky údaje o zdroji pre systém PS. Dokumentom sa môžete dozvedieť o webových stránkach indexovaných prácami.
Súbor poskytuje rýchly prístup k PS na ľubovoľnú stránku, zobrazuje najnovšie zmeny, frekvenciu a dôležitosť PS. Podľa týchto kritérií robot najviac správne naskenuje lokalitu. Je však dôležité pochopiť, že prítomnosť takéhoto súboru nezaručuje, že všetky stránky sú indexované. Je to skôr pokyn na ceste k tomuto procesu.
Použitie
Správny súbor robots.txt sa používa dobrovoľne. Samotný štandard sa objavil v roku 1994. Bol prijatý konzorciom W3C. Od tohto okamihu sa začalo používať takmer vo všetkých vyhľadávačoch. Vyžaduje sa pri "dávkovanom" nastavení skenovania zdrojov pomocou vyhľadávacieho robota. Súbor obsahuje súbor pokynov, ktoré používajú FP. Vďaka súboru nástrojov je ľahké inštalovať súbory, stránky a adresáre, ktoré nie je možné indexovať. Robots.txt tiež odkazuje na súbory, ktoré je potrebné ihneď skontrolovať.
Prečo?
Napriek skutočnosti, že súbor sa môže skutočne použiť dobrovoľne, vytvára prakticky všetky stránky. To je potrebné na zjednodušenie práce robota. V opačnom prípade skontroluje všetky stránky v náhodnom poradí a okrem toho, že dokáže preskočiť niektoré stránky, vytvára ťažké zaťaženiezdroj. Súbor sa tiež skrýva z očí vyhľadávača:
Stránky s osobnými údajmi návštevníkov.
Stránky obsahujúce formuláre na odosielanie údajov atď.
Zrkadlové stránky.
Stránky s výsledkami vyhľadávania.
Ak ste pre konkrétnu stránku zadali súbor robots.txt, existuje šanca, že sa bude stále zobrazovať vo vyhľadávači. Táto možnosť sa môže vyskytnúť, ak je odkaz na stránku umiestnený na niektorom z externých zdrojov alebo na vašom webe.
Smernice
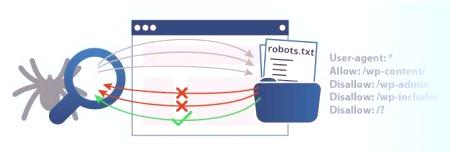
Keď už hovoríme o zákaze vyhľadávača, často sa používa termín "smernice". Tento termín je známy všetkým programátorom. Často sa nahrádza synonymom "inštrukcie" a používa sa v spojení s "príkazmi". Niekedy to môže byť reprezentované súborom konštruktov programovacích jazykov. Smernica Disallow v súbore robots.txt je jedným z najbežnejších, ale nie jediný. Okrem toho existuje niekoľko ďalších, ktorí sú zodpovední za určité pokyny. Napríklad existuje používateľský agent, ktorý zobrazuje roboty vyhľadávačov. Povoliť je opačný nepovolaný príkaz. Označuje povolenie indexovo prehľadávať niektoré stránky. Ďalej sa pozrime na základné príkazy.
Vizitka
Samozrejme, v súbore robots.txt, User Agent Disallow nie je jedinou smernicou, ale jedným z najbežnejších. Skladá sa z väčšiny súborov pre malé zdroje. Vizitka pre ľubovoľný systém je stále príkazom User Agent. Toto pravidlo je navrhnuté tak, aby poukazovalo na roboty, ktoré sa pozerajú na pokyny, ktoré sa zapíšu do dokumentu. V súčasnosti je k dispozícii 300 vyhľadávacích nástrojov. Ak chcete, aby každý z nich nasledovalNiekto by nemal všetko prepísať sotva. Bude stačiť špecifikovať "User-agent: *". "Asterisk" v tomto prípade zobrazí systémy, ktoré sú navrhnuté pre všetky vyhľadávače. Ak vytvárate pokyny pre Google, potom musíte zadať názov robota. V takom prípade použite Googlebot. Ak je v dokumente zadaný iba názov, ostatné vyhľadávacie nástroje nebudú prijímať príkazy súboru robots.txt: Zakázať, Povoliť atď. Predpokladajú, že dokument je prázdny a neexistujú žiadne pokyny.
Úplný zoznam botov možno nájsť na internete. Je to veľmi dlhé, takže ak potrebujete pokyny pre určité služby Google alebo Yandex, budete musieť špecifikovať konkrétne mená.
Zákaz
Už sme hovorili o ďalšom tíme mnohokrát. Zakázať práve špecifikuje, ktoré informácie by robot nemal čítať. Ak chcete zobraziť vyhľadávaciemu zariadeniu celý svoj obsah, stačí napísať "Zakázať:". Práca tak skenuje všetky stránky vášho zdroja. Úplný zákaz indexovania súborov robots.txt "Zakázať: /". Ak píšete takto, práca nebude zdroj skenovať vôbec. Zvyčajne sa to robí v počiatočných fázach, pri príprave na spustenie projektu, pri pokusoch atď. Ak je stránka pripravená prezentovať sa, potom túto hodnotu zmeniť tak, aby sa s ňou mohli používatelia oboznámiť. Tím vo všeobecnosti je univerzálny. Môže blokovať určité položky. Napríklad priečinok s príkazom Disallow: /papka /môže zakázať prehľadávanie odkazu na súbor alebo dokumenty s konkrétnym povolením.
Povolenie
Povolenie práceprezeranie určitých stránok, súborov alebo adresárov pomocou smernice Allow. Niekedy je potrebný príkaz, aby robot navštívil súbory z konkrétnej sekcie. Ak je napríklad online obchod, môžete zadať adresár. Ďalšie stránky budú naskenované. Pamätajte však, že musíte najskôr zastaviť zobrazenie celého obsahu a určiť príkaz Povoliť s otvorenými stránkami.
Zrkadlá
Ďalšia hostiteľská smernica. Nepoužívajú ho všetci webmasteri. Je to potrebné, ak váš zdroj zrkadlí. Toto pravidlo je potrebné, pretože označuje prácu "Yandex", na ktorej zrkadlách je hlavná a ktorá musí byť skenovaná. Systém sa nestará a ľahko nájde požadovaný zdroj podľa pokynov popísaných v súbore robots.txt. V samotnom súbore je web napísaný bez uvedenia "http: //", ale iba ak funguje na HTTP. Ak používa protokol HTTPS, označuje túto predponu. Napríklad "Host: site.com" ak HTTP alebo "Host: https://site.com" v prípade HTTPS.
Navigátor
Hovorili sme o súboroch Sitemap, ale ako samostatný súbor. Pri pohľade na pravidlá pre písanie robots.txt s príkladmi vidíme použitie podobného príkazu. Súbor odkazuje na súbor Sitemap: http://site.com/sitemap.xml. Robí to tak, že robot skontroluje všetky stránky, ktoré sú uvedené na mape stránky na adrese. Vždy, keď sa vrátite, robot uvidí nové aktualizácie, vykonané zmeny a rýchlejšie odosielanie údajov do vyhľadávača.
Ďalšie príkazy
Toto boli základné pokyny, ktoré poukazujú na dôležité a potrebné príkazy. Existujú menej užitočné apokyny nie sú vždy používané. Napríklad oneskorenie indexového prehľadávania určuje obdobie, ktoré sa má používať medzi načítaním stránok. Toto je potrebné pre slabé servery, aby sa "neposkytovali" do robotov robotov. Na stanovenie parametra sa používajú sekundy. Program Clean-param pomáha vyhnúť sa duplicitnému obsahu, ktorý sa nachádza na rôznych dynamických adresách. Vznikajú, ak existuje funkcia triedenia. Toto bude vyzerať takto: "Clean-param: ref /catalog /get_product.com".
Universal
Ak neviete, ako vytvoriť správny súbor robots.txt - nie strašidelný. Okrem pokynov existujú univerzálne verzie tohto súboru. Môžu byť umiestnené na prakticky ľubovoľnej webovej stránke. Výnimka môže byť len veľkým zdrojom. V tomto prípade by však mali byť spisy známe odborníkom a zapojiť ich do špeciálnych ľudí.
Univerzálny súbor smerníc vám umožňuje otvoriť obsah stránky na indexovanie. Tu je názov hostiteľa a je zobrazená mapa stránok. Umožňuje robotom vždy prístup na stránky, ktoré sa majú skenovať. Predpokladá sa, že údaje sa môžu líšiť v závislosti od systému, ktorý má váš zdroj. Preto je potrebné zvoliť pravidlá, pričom sa pozrieme na typ stránky a CMS. Ak si nie ste istí, že súbor, ktorý ste vytvorili, je správny, môžete ho skontrolovať v Nástrojoch správcu webu Google a v nástroji Yandex.
Chyby
Ak pochopíte, čo znamená Disallow v robots.txt, to nezaručuje, že pri vytváraní dokumentu nebudete robiť chyby. Existuje niekoľko typických problémov, s ktorými sa stretávajú neskúsení používatelia. Často zamieňajú hodnotu smernice. Môže to byťspojené s nepochopením a neznalosťou vedením. Práve ste nedohlediv a mimovoľne zmiešané. Napríklad môže byť použitý pre hodnoty User-agent "/" a názov Zakázať prácu. Prevod je ďalšou bežnou chybou. Niektorí ľudia sa domnievajú, že prevod zakázaných stránok, súborov alebo priečinkov na určenie riadku v rade. V skutočnosti, pre každého zakázaných alebo povolených odkazy, súbory a priečinky, ktoré potrebujú, aby znovu spolupracovať s novú líniu. Chyby môžu byť spôsobené zlým názvom súboru. Pamätajte, že sa nazýva "robots.txt". Použiť malá mená, bez zmeny typu «Robots.txt» alebo «robots.txt».
Pole User-agent by sa vždy mala vyplniť. Nenechávajte túto smernicu bez príkazu. Opäť platí, že návrat k hostiteľovi, si uvedomiť, že v prípade, že web používa protokol HTTP, ukazujú, že tím nepotrebuje. Iba ak je to rozšírená verzia protokolu HTTPS. Nemôžete nechať smernicu Disallow bezvýznamnú. Ak ju nepotrebujete, jednoducho ho neuvádzajte.
Záver
V súhrne, povedať, že robots.txt - štandard, ktorý vyžaduje presnosť. Ak ste s ním nikdy nemal, v prvej fáze vás tam bude veľa otázok. Je lepšie, aby tú prácu webmasterov, ako sú dokumenty po celú dobu. Okrem toho môžu existovať určité zmeny vo vnímaní smerníc vo vyhľadávačoch. Ak máte malé stránky - malý internetový obchod alebo blog - potom to bude stačiť na štúdium tohto problému a vykonať jednu z univerzálnych príkladov.